
本文会讲述我在毕设中用到的 “在 iOS 中渲染 Markdown ” 以及 “关键字提取的简单方法” 。
在 iOS 中渲染 markdown
GitHub: RoomTime
Markdown 其实与 HTML 关联的。所以在 iOS 中原生渲染 markdown 可能不是一件“合理”的事。一些渲染 markdown 的 JS 库通常的做法是:
用正则匹配 markdown 中的语法,并用 HTML 标签包裹匹配的结果。比如:
Hello **markdown** !会被(初步)渲染成:
Hello <strong>markdown</strong> !让浏览器自己去渲染生成的 HTML 。
同样地,iOS 可以:
将 markdown 构建成类似 HTML 的元素树。
将元素树渲染成视图。
实现及难点
一个渲染器除了将文本转为视图,还要考虑:
对文本进行预加工处理(比如规范空白符)。
能够让用户自定义语法、以及要渲染的视图的样式。
实现方法
这个实现方法大概能满足我的 80% 的渲染需求。
将文本根据一系列规则进行分割(或转换)。
将分割出来的文本转为元素。
将元素转为要呈现的视图。
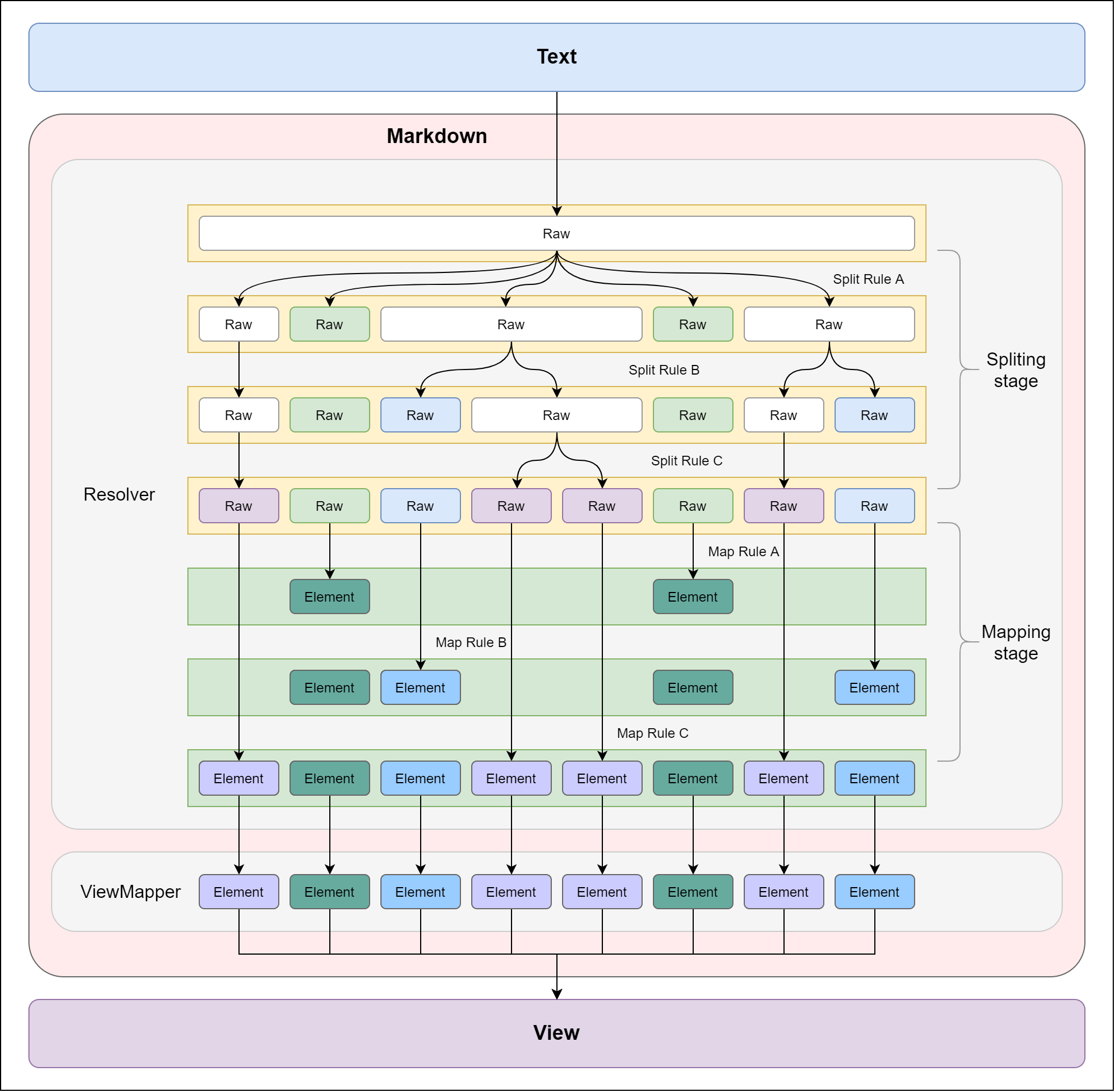
难点及遇到的问题
缩进的识别
1. fruit
- apple
- banana
- melon
2. pet
- cat
- dog语法优先级
```css
// 通用选择器
* {
color: hotpink;
}
```- 通用选择器
```css
* {
color: hotpink;
}
```
- 类选择器...
关键字提取的简单方法
分词:从句子中分出短语。
筛选:将没用的介词、连词、代词等去除。
评估:计算一个词的关键程度。
前两个涉及 NLP(Natural Language Processing ,即自然语言处理),我直接用了工具。
评估方法可以使用最简单的 TF-IDF :
TF-IDF
TF-IDF 关注两个维度:
TF :即 Term frequency ,词频。
TF = 词在该文章中的次数 / 该文章的总词数IDF :即 Inverse document frequency ,反文档频率。
如果一个词在许多文章中均出现,那么它通常不能成为关键词。
IDF = log( 文章数量 / 词在多少篇文章出现过 ) + 1
一个词的 TF-IDF 值则为:
TF-IDF = TF * IDF
对于 markdown 可能还要考虑词的权重。比如一个词如果在标题中出现过,它应当更适合当关键词;在代码块中的词不应当被统计。
参考
Understanding TF-ID: A Simple Introduction - MonkeyLearn
sklearn.feature_extraction.text.TfidfTransformer - scikit-learn